Spark 튜닝
RDD 사용 자제
Spark 작업의 경우 RDD보다 Dataset/DataFrame을 Dataset으로 사용하는 것이 좋습니다.
DataFrame에는 Spark 워크로드의 성능을 개선하기 위한 여러 최적화 모듈이 포함되어 있습니다. PySpark 사용에서 Dataset의 RDD를 통한 DataFrame은 PySpark 애플리케이션에서 지원되지 않습니다.
RDD를 사용하면 스파크가 최적화 기술을 적용하는 방법을 모르기 때문에 성능 문제가 직접 발생하고 RDD는 클러스터에 분산(재파티션 및 셔플링)할 때 데이터를 직렬화 및 역직렬화함. 직렬화 및 역직렬화는 Spark 애플리케이션 또는 모든 분산 시스템에서 매우 비용이 많이 드는 작업
Spark SQL
Spark SQL 및 DataFrame API는 Spark SQL의 최적화된 실행 엔진을 통해 사용 편의성, 공간 효율성 및 성능 향상을 제공합니다.

https://www.nvidia.com/ko-kr/ai-data-science/spark-ebook/spark-sql-dataframes/#p5-s1
Spark SQL은 필요한 열만 스캔하고, 압축을 자동으로 조정하며, 메모리 사용을 최소화하며, JVM 가비지 수집을 최소화하는 데 최적화된 메모리 내 열 기반 형식을 사용하여 DataFrame을 캐시(dataFrame.cache 호출 시)합니다
repartition() 대신 coalesce() 사용
Partitioning

https://blog.scottlogic.com/2018/03/22/apache-spark-performance.html
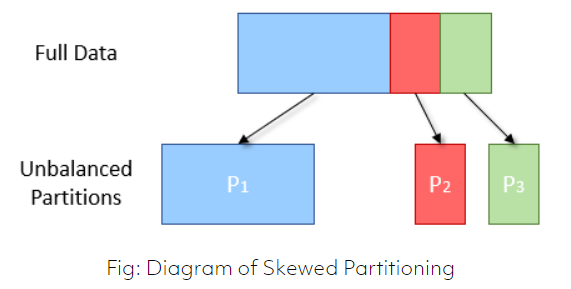
Spark cluster와 같은 병렬 환경에서는, 데이터를 알맞게 쪼개어주는 것이 매우 중요합니다. 그래야 각 executor node가 놀지 않고 일을 할 수 있습니다.
https://blog.scottlogic.com/2018/03/22/apache-spark-performance.html
잘 쪼개지지 않은 데이터를 가지고 일을 시키면, 특정 node에게만 일이 몰리는 현상이 발생할 수 있는데 이를 데이터가 skew 되었다고 합니다.
join 연산 등이 빈번하게 일어나는 job의 경우에는 미리 해당 설정값을 적절히 조절해주는 것으로 적당한 partition 개수를 유지해야합니다.
프로그래머가 통제할 수 있는 상황에서는 coalesce나 repartition 함수를 통해 partition 개수를 적절히 설정해줄 수 있지만, 프로그래머가 통제할 수 없는 상황도 있습니다. 바로 join 등과 같이 imply shuffling이 일어날 때인데요. 이때는 Spark 설정값인 spark.sql.shuffle.partitions 값으로 partition 개수가 정해집니다.
repartition vs coalesce
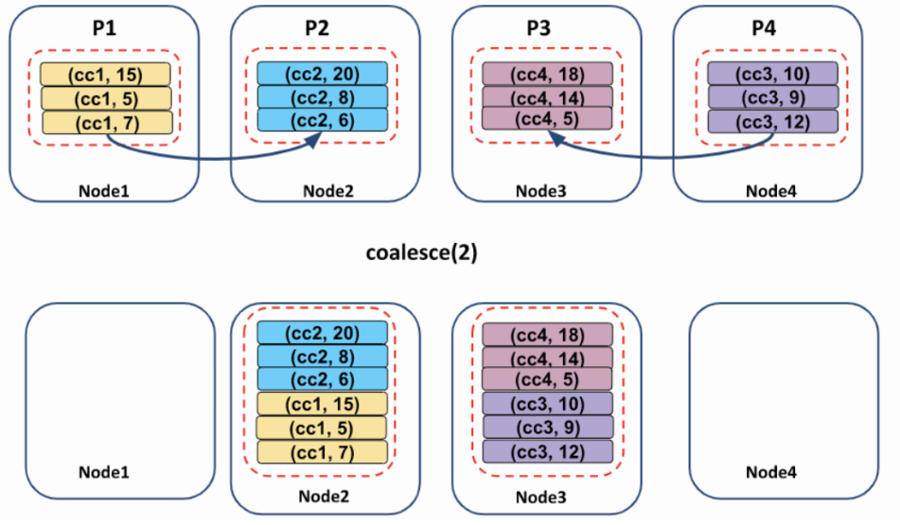
파티션 수를 줄이려는 경우 더 큰 데이터 세트를 처리할 때 이상적으로 더 잘 수행되는 병합을 사용하여 파티션 간 데이터 이동이 더 낮은 최적화 coalesce()되거나 개선된 버전이므로 사용하는 것이 좋습니다.

https://dongza.tistory.com/18
repartition 함수는 shuffling을 유발합니다. repartition 자체가 전체 데이터를 node 사이에 균등하게 분배해주는 것이기 때문에 shuffle이 일어납니다.
coalesce 함수를 사용하게 되면 partition 개수를 늘릴 수 없는 제약이 있는 대신에, shuffle을 유발하지 않고도 데이터를 분배합니다.
def coalesce(numPartitions: Int): Dataset[T] = withTypedPlan { Repartition(numPartitions, shuffle = false, planWithBarrier) } def repartition(numPartitions: Int): Dataset[T] = withTypedPlan { Repartition(numPartitions, shuffle = true, planWithBarrier) }
map() 대신 mapPartitions() 사용
Spark map()및 mapPartitions()변환은 DataFrame/Dataset의 각 요소/레코드/행에 함수를 적용하고 새 DataFrame/Dataset를 반환합니다.
map()보다 mapPartitions() 는 클래스 초기화, 데이터베이스 연결 등과 같은 초기화가 많은 경우 성능 향상을 미리 제공합니다.
Spark mapPartitions() 는 모든 DataFrame 행에서 수행하는 대신 각 파티션에 대해 한 번에 대량 초기화(예: 데이터베이스 연결)를 수행할 수 있는 기능을 제공합니다.
직렬화된 데이터 형식 사용

https://dkharazi.github.io/blog/parquet

https://starship-knowledge.com/apache-avro
Avro, Kryo, Parquet 등과 같은 직렬화되고 최적화된 형식으로 중간 파일을 작성하는 것을 선호합니다. 이러한 형식의 변환은 텍스트, CSV 및 JSON 보다 더 잘 수행 됨
Serializer 선택

https://hazelcast.com/glossary/serialization/
Scala의 가장 큰 장점 중 하나는 바로 case class 라고 생각합니다. case class와 Spark를 결합하면 큰 노력없이 type strict한 코드를 작성할 수 있는데요. 문제는 사용자가 case class를 사용하면 Spark가 각 object를 node 사이에 분배할 때 serialization/deserialization이 일어나게 됩니다. (SerDe 입니다.)
Spark 2.x 버전을 기준으로, Spark는 두 가지 형태의 serializer를 지원하는데요. 기본값으로 설정되어 있는 Java serializer와 성능이 월등히 개선된 Kyro serializer가 그 주인공입니다. 어떤 이유에선지 Kyro가 성능이 훨씬 좋음에도 불구하고 기본 serializer로 설정되어 있지 않아, 사용자가 다음 설정을 통해 Kyro를 사용하도록 만들어줘야 합니다.
spark.serializer “org.apache.spark.serializer.KryoSerializer”
Apache Parquet는 쿼리 속도를 높이는 최적화를 제공하는 열 형식 파일 형식이며 많은 데이터 처리 시스템에서 지원하는 CSV 또는 JSON보다 훨씬 효율적인 파일 형식
장점
IO 작업을 줄입니다.
액세스해야 하는 특정 열을 가져옵니다.
공간을 덜 차지합니다.
유형별 인코딩을 지원합니다.
Apache Avro 는 원래 Avro 파일 형식의 데이터 읽기 및 쓰기를 지원하는 오픈 소스 라이브러리로 databricks에서 개발한 Hadoop 프로젝트용 오픈 소스, 행 기반, 데이터 직렬화 및 데이터 교환 프레임워크
장점
배열, 맵, 맵 배열 및 배열 요소 맵과 같은 복잡한 데이터 구조를 지원합니다.
데이터를 전송하는 동안 빠른 속도를 제공하는 컴팩트한 이진 직렬화 형식입니다.
행 기반 데이터 직렬화 시스템.
다중 언어를 지원합니다. 즉, 한 언어로 작성된 데이터를 다른 언어로 읽을 수 있습니다.
데이터 파일을 읽거나 쓰기 위해 코드 생성이 필요하지 않습니다. 동적 언어와의 간단한 통합.
UDF(사용자 정의 함수)를 피하십시오


https://medium.com/wbaa/using-scala-udfs-in-pyspark-b70033dd69b9
UDF는 Spark에 대한 블랙박스이므로 최적화를 적용할 수 없으며 Spark가 Dataframe/Dataset에서 수행하는 모든 최적화를 잃게 됩니다. 가능하면 Spark SQL 기본 제공 함수 를 사용해야 합니다. 이러한 함수는 최적화를 제공함
메모리에 데이터 지속 및 캐싱

https://www.learntospark.com/2020/05/persist-and-cache-in-apache-spark.html
Spark 지속/캐싱은 Spark 워크로드의 성능을 향상시키는 최고의 기술 중 하나입니다.
cache() 메서드는 데이터 를 메모리에 저장(MEMORY_ONLY) 하는 반면 persist() 메서드에서는 개발자가 스토리지를 정의할 수 있다는 점만 다릅니다.
Spark Cache 및 Persist는 반복 및 대화형 Spark 애플리케이션을 위한 DataFrame/Dataset의 최적화 기법으로 작업의 성능을 향상 시킵니다 .
cache() 및 persist()는 Spark는 후속 작업에서 재사용할 수 있도록 Spark DataFrame의 중간 계산을 저장하는 최적화 메커니즘을 제공함
Spark Cache 및 Persist 방식을 사용할 때의 장점
비용 효율적 – Spark 계산은 비용이 많이 들기 때문에 계산을 재사용하여 비용을 절감합니다.
시간 효율성 – 반복 계산을 재사용하면 많은 시간이 절약됩니다.
실행 시간 – 작업 실행 시간을 절약하고 동일한 클러스터에서 더 많은 작업을 수행할 수 있습니다.
값비싼 셔플 작업 감소
https://blog.scottlogic.com/2018/03/22/apache-spark-performance.html
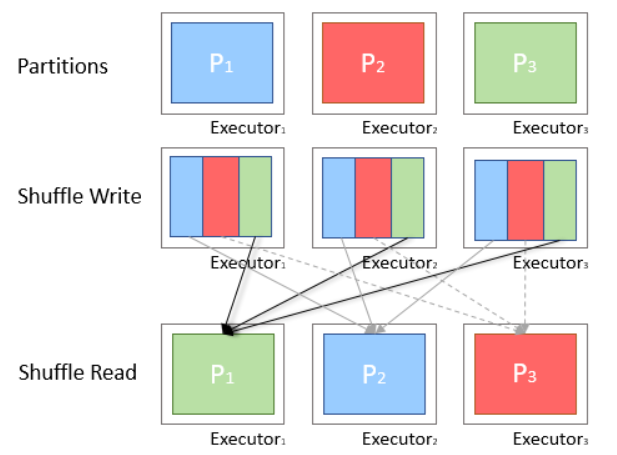
스파크 셔플링은 RDD 및 DataFrame에서 gropByKey(), reducebyKey()와 같은 특정 변환 작업을 수행할 때 트리거됩니다.
스파크 셔플은 다음을 포함하므로 비용이 많이 드는 작업입니다.
디스크 I/O
데이터 직렬화 및 역직렬화 포함
네트워크 I/O
groupByKey 와 reduceByKey

https://stackoverflow.com/questions/36042743/what-happen-internally-when-we-join-two-dstream-grouped-by-keys
reduceByKey로 해결할 수 있는 문제 상황에서는 무조건 reduceByKey를 사용해야함
groupByKey를 쓰게 되면 Spark에서 가장 기피해야할 Data shuffling이 모든 node 사이에서 일어나게 됩니다.
reduceByKey는 shuffle 하기 전에 먼저 reduce 연산을 수행해서 네트워크를 타는 데이터를 현저히 줄여줍니다. 그래서 가급적이면 reduceByKey나 aggregateByKey 등 shuffling 이전에 데이터 크기를 줄여줄 수 있는 함수를 먼저 고려해야 함
High-level API 사용하기
Spark 2.x 부터는 Dataset API를 사용하는 것이 권장됩니다. 물론 Dataset도 내부 뼈대는 여전히 RDD지만, 다양한 최적화 (Catalyst optimization 등) 기법과 훨씬 더 강력한 인터페이스를 포함하고 있습니다.
Spark SQL의 Catalyst Optimizer는 논리적 최적화 및 물리적 계획을 처리하여 규칙 기반 및 비용 기반 최적화를 모두 지원합니다.

https://www.databricks.com/glossary/catalyst-optimizer

https://www.unraveldata.com/resources/catalyst-analyst-a-deep-dive-into-sparks-optimizer/
예를 들어, 시간이 많이 걸리는 join 연산을 수행할 때 High-level API를 사용하면 가능한 경우에 자동으로 Broadcast join 등으로 바꿔 shuffle이 일어나지 않게 해주는 최적화가 이루어집니다. 그래서 가급적이면 Dataset이나 Dataframe을 이용해서 Spark 코드를 짜는것을 추천드립니다.
LowerBound / UpperBound

https://medium.com/mercedes-benz-techinnovation-blog/increasing-apache-spark-read-performance-for-jdbc-connections-a028115e20cd
Sqoop과 유사하게 Spark는 Spark 실행기에 의해 생성된 다른 작업에서 병렬로 추출할 데이터에 대한 분할 또는 파티션을 정의할 수도 있습니다.
ParitionColumn은 Sqoop의 split-by 옵션과 동일합니다.
LowerBound 및 UpperBound는 기본 키의 최소 및 최대 범위를 정의한 다음 Spark가 범위를 여러 작업으로 나누어 데이터 추출을 병렬화할 수 있도록 하는 numPartitions와 함께 사용됩니다. NumPartitions는 또한 데이터베이스에 대한 동시 JDBC 연결의 최대 수를 정의합니다. 실제 동시 JDBC 연결은 작업에 사용 가능한 Spark 실행기 수에 따라 이 수보다 낮을 수 있음
Reference
https://www.slideshare.net/SangbaeLim/cloudera-sessions-seoul-spark-bootcamp
https://sparkbyexamples.com/spark/spark-performance-tuning/?amp=1#udf
https://nephtyws.github.io/data/spark-optimization-part-1/
Last updated