spark_optimization
최적화 포인트
Spark 에는 최적화 기능들(optimizer) 을 갖추고 있습니다.
1.x 버전에서는 Rule-Based Optimizer만 갖고 있었습니다.
2.x 버전에서 Cost-Based Optimizer가 추가되었습니다.
3.x 버전에는 Adaptive Query Execution(AQE) 추가되었습니다.
AQE(Adaptive Query Execution)
- https://www.databricks.com/blog/2020/05/29/adaptive-query-execution-speeding-up-spark-sql-at-runtime.html
실행 시간 동안 쿼리의 실행 계획을 동적으로 재조정하고 최적화합니다. AQE는 실행 계획을 최적화하기 위해 런타임 통계를 활용합니다.
동적 셔플 파티션 통합(Dynamically coalescing shuffle partitions)
셔플 이후에 생성된 파티션의 크기가 너무 작거나 불균형적인 경우, AQE는 이러한 파티션들을 동적으로 통합하여 파티션 수를 줄입니다. 이를 통해 소량의 데이터를 가진 파티션에 대한 오버헤드를 줄이고 전체 쿼리의 실행 속도를 향상시킵니다.
동적 전환 조인 전략(Dynamically switching join strategies)
조인 연산을 실행하기 전에 실제 데이터 크기를 확인하고, 이를 기반으로 가장 적합한 조인 전략 (예: broadcast join, sort-merge join)으로 동적으로 전환합니다.
스큐 조인을 동적으로 최적화(Dynamically optimizing skew joins)
조인 연산 시 한쪽의 데이터 분포가 매우 불균형적인 경우 (즉, 스큐가 있는 경우), AQE는 이 스큐를 인식하고 해당 파티션을 세분화하여 조인 성능을 향상시킵니다.
최적화 포인트
코드 수준의 설계(예: RDD와 DataFrame 중 하나를 선택함)
보관용 데이터
조인
집계
데이터 전송
애플리케이션별 속성
익스큐터 프로세스의 JVM
워커 노드
클러스터와 배포 환경 속성
DataFrame vs SQL vs Dataset vs RDD
모든 언어에서 DataFrame, Dataset 그리고 SQL의 속도는 동일합니다. DataFrame은 어떤 언어에서 사용하더라도 성능은 동일합니다.
파이썬이나 R을 사용해 UDF를 정의하면 성능 저하가 발생할 수 있으므로 자바와 스칼라를 사용해 UDF를 정의하는 것이 좋습니다.
파이썬에서 RDD 코드를 실행한다면 파이썬 프로세스를 오가는 많은 데이터를 직렬화해야합니다., 매우 큰 데이터를 직렬화하면 엄청난 비용이 발생하고 안정성까지 떨어질 수 있습니다.
RDD

https://phoenixnap.com/kb/resilient-distributed-datasets
DataFrame의 각 레코드는 스키마를 알고 있는 필드로 구성된 구조화된 로우인 반면, RDD의 레코드는 그저 프로그래머가 선택한 자바, 스칼라, 파이썬의 객체일뿐 RDD API는 Dataset과 유사하지만 RDD는 구조화된 데이터 엔진을 사용해 데이터를 저장하거나 다루지 않습니다. RDD와 Dataset 사이의 전환은 매우 쉬우므로 두 API를 모두 사용해 각 API의 장점을 동시에 활용합니다.
Low Level API - Resilient Distributed Dataset (RDD)은 스파크 프로그래밍의 기본입니다. 주로 RDD는 클러스터의 노드(작업자) 간에 분할된 요소 모음으로 노드에서 병렬 작업을 쉽게 제공합니다.

https://www.databricks.com/blog/2015/02/17/introducing-dataframes-in-spark-for-large-scale-data-science.html
https://phoenixnap.com/kb/rdd-vs-dataframe-vs-dataset
DataFrame

https://www.nvidia.com/ko-kr/ai-data-science/spark-ebook/introduction-spark-processing/#p3-s1
Spark SQL 및 DataFrame API는 Spark SQL의 최적화된 실행 엔진을 통해 사용 편의성, 공간 효율성 및 성능 향상을 제공합니다.
모듈식(일명 재사용 가능)으로 쉽게 단위 테스트 가능.읽기가 쉬우며 논리가 분해되고 캡슐화됩니다.
DataFrame이 Catalyst 옵티마이저를 통과하여 Spark SQL 쿼리와 유사한 최적화된 실행을 가능하게 한다는 것입니다.
Spark sql

https://www.nvidia.com/ko-kr/ai-data-science/spark-ebook/spark-sql-dataframes/
Spark SQL은 필요한 열만 스캔하고, 압축을 자동으로 조정하며, 메모리 사용을 최소화하며, JVM 가비지 수집을 최소화하는 데 최적화된 메모리 내 열 기반 형식을 사용하여 DataFrame을 캐시(dataFrame.cache 호출 시)합니다.
컴팩트, 모든 논리가 함께, 단위 테스트는 덜 사소하지만 불가능하지는 않습니다.읽기 쉬우며 아마도 쉽게 재사용하지 못할 것입니다
DataFrame 사용자들은 SparkSQL 사용에 대해 무엇을 배울 수 있는점
때로는 복잡한 변환의 가독성이 더 쉽게 따르고 SQL로 마음을 감쌀 수 있습니다.
SparkSQL에서 사용할 수 있는 CTE와 같은 멋진 기능 사용 가능합니다.
일부 변환은 SparkSQL에서 더 쉽고 더 짧은 양의 코드일 수 있습니다
SparkSQL 사용자는 DataFrame을 사용하여 배울 수 있는점
단위 테스트의 용이함과 중요성
코드를 더 모듈화하고 재사용 가능하게 만들기
SQL을 사용하는 대신 더 나은 코드를 작성하는 방법을 배우고 프로그래밍에 익숙해지는 것입니다.
테이블 파티셔닝

https://selectfrom.dev/apache-spark-partitioning-bucketing-3fd350816911
파티션은 데이터를 지역화하고 네트워크 노드에서 데이터 셔플링을 줄여 변환 작업의 주요 구성 요소인 네트워크 대기 시간을 줄여 완료 시간을 줄이는 데 도움이 됩니다.

https://selectfrom.dev/apache-spark-partitioning-bucketing-3fd350816911
테이블 파티셔닝은 데이터의 날짜 필드를 같은 키를 기준으로 개별 디렉터리에 파일을 저장하는 것을 의미합니다.
쿼리에서 컬럼을 기준으로 자주 필터링한다면 컬럼을 기준으로 파티션을 생성하는 것이 좋습니다.
파티셔닝을 사용하면 쿼리에서 읽어야 하는 데이터양을 크게 줄일 수 있어 쿼리를 훨씬 빠르게 처리할 수 있습니다.
파티셔닝을 할 때 너무 작은 단위로 분할하면 작은 크기의 파일이 대량으로 생성될 수 있고 저장소 시스템에서 전체 파일의 목록을 읽을 때 오버헤드가 발생합니다.
데이터를 파티션이나 버켓으로 구성하려면 파일 수와 저장하려는 파일 크기도 고려해야합니다.
작은 파일이 많은 경우 파일 목록 조회와 파일 읽기 과정에서 부하가 발생합니다.
트레이드 오프를 감안해야합니다.
입력 데이터 파일이 최소 수십 메가바이트의 데이터를 갖도록 파일의 크기를 조정하는것이 좋습니다.
버켓팅

https://selectfrom.dev/apache-spark-partitioning-bucketing-3fd350816911
Bucketing 은 작업 성능을 최적화하는 데 사용되는 Spark 및 Hive의 기술입니다. 버킷팅 버킷( 클러스터링 열 )에서 데이터 파티셔닝을 결정하고 데이터 셔플을 방지합니다. 하나 이상의 버킷 열 값에 따라 데이터가 미리 정의된 버킷 수에 할당됩니다.

https://www.nvidia.com/ko-kr/ai-data-science/spark-ebook/spark-sql-dataframes/
파일 분할 및 버킷은 Spark SQL에서 일반적인 최적화 기술입니다. 파일이나 디렉토리에서 데이터를 미리 집계하여 데이터 왜곡 및 데이터 축소를 줄이는 데 도움이 될 수 있습니다
분할 가능한 포맷을 사용하면 여러 태스크가 파일의 서로 다른 부분을 동시에 읽을 수 있음
데이터를 버켓팅하면 스파크는 사용자가 조인이나 집계를 수행하는 방식에 따라 데이터를 사전 분할(pre-partition)할 수 있습니다.
데이터를 한두 개 파티션에 치우치지 않고 전체 파티션에 균등하게 분산시킬 수 있습니다.
Hive vs Spark

https://selectfrom.dev/apache-spark-partitioning-bucketing-3fd350816911
Hive에서는 생성해야 하는 파일 수를 기반으로 하는 리듀서가 필요합니다. Spark 버킷팅에는 리듀서가 없습니다. 따라서 작업 수에 따라 n개의 파일을 생성하게 됩니다.
파일 기반 장기 데이터 저장소
데이터를 바이너리 형태로 저장하려면 구조적 API를 사용하는 것이 좋습니다.
CSV 같은 파일은 구조화되어 있는 것처럼 보이지만 파싱 속도가 아주 느리고 예외 상황이 자주 발생합니다.
파케이는 데이터를 바이너리 파일에 컬럼 지향 방식으로 저장합니다.
쿼리에서 사용하지 않는 데이터를 빠르게 건너뛸 수 있도록 몇 가지 통계를 함께 저장합니다.
셔플 설정


https://engineering.linkedin.com/blog/2020/introducing-magnet
스파크의 외부 셔플 서비스를 설정하면 머신에서 실행되는 익스큐터가 바쁜 상황에서도(예:가비지 컬렉션 수행) 원격 머신에서 셔플 데이터를 읽을 수 있으므로 성능을 높일 수 있습니다.
파티션 수가 너무 적으면 소수의 노드만 작업을 수행하기 때문에 데이터 치우침 현상이 발생합니다.
파티션 수가 너무 많으면 파티션을 처리하기 위한 태스크를 많이 실행해야 하므로 부하가 발생합니다.
셔플을 수행할 때는 결과 파티션당 최소 수십 메가바이트의 데이터가 포함되어야 합니다.
메모리 부족과 가비지 컬렉션
스파크 잡 실행 과정 중에 익스큐터나 드라이버 머신의 메모리가 부족하거나 메모리 압박(memory pressure)으로 인해 태스크를 완료하지 못할 수 있습니다.
애플리케이션 실행 중에 메모리를 너무 많이 사용한 경우
가비지 컬렉션이 자주 수행되는 경우
JVM 내에서 객체가 너무 많이 생성되어 더 이상 사용하지 않는 객체를 가비지 컬렉션이 정리하면서 실행 속도가 느려지는 경우
가비지 컬레션의 튜닝
https://www.databricks.com/blog/2015/05/28/tuning-java-garbage-collection-for-spark-applications.html
가비지 컬렉션의 발생 빈도와 소요 시간에 대한 통계를 모으는 것, spark.executor.extraJavaOptions 속성에 스파크 JVM 옵션으로 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps 값을 추가해 통계를 모을 수 있습니다.
속성값을 설정한 다음 스파크 잡을 실행하면 가비지 컬렉션이 발생할 때매다 워커의 로그에 메시지가 출력됩니다.
로그는 드라이버가 아닌 워커 노드의 stdout 파일에 저장됩니다.
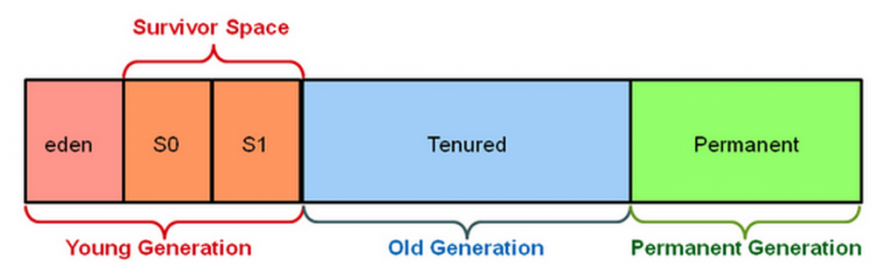
자바 힙 공간은 Young 영역과 Old 영역으로 나누어짐, Young 영역은 수명이 짧은 객체를 유지하고 반면 Old 영역은 오래 살아 있는 객체를 대상으로 합니다.
Young 영역은 Eden, Survivor1, Survivor2 세 영역으로 다시 나뉩니다.
가비지 컬렉션 수행 절차
Eden 영역이 가득 차면 Eden 영역에 대한 마이너 가비지 컬렉션(minor garbage collection)이 실행됨, Eden 영역에서 살아남은 객체와 Survivor1 영역의 객체는 Survivor2 영역으로 복제됩니다.
두 Survivor 영역을 교체합니다.
객체가 아주 오래되었거나 Survivor2 영역이 가득 차면 객체는 Old 영역으로 옮겨집니다.
마지막으로 Old 영역이 거의 가득 차면 풀 가비지 컬렉션(full garbage collection)이 발생합니다. 풀 가비지 컬렉션은 힙 공간의 모든 객체를 추적해 참조 정보가 없는 객체들을 제거하고 나머지 객체를 빈곳으로 옮기는 작업을 수행합니다. 풀 가비지 컬렉션은 가장 느린 가비지 컬렉션 연산입니다.
수명이 긴 캐시 데이터셋을 Old 영역에 저장함, Young 영역에서 수명이 짧은 모든 객체를 보관할 수 있도록 충분한 공간을 유지합니다.
스파크 잡의 성능 튜닝 방법
속성값을 설정하거나 런타임 환경을 변경해 간접적으로 성능을 높입니다. 전체 스파크 애플리케이션이나 스파크 잡에 영향을 미칩니다.
개별 스파크 잡, 스테이지, 태스크 성능 튜닝을 시도하거나 코드 설계를 변경해 직접적으로 성능을 높일 수 있음, 애플리케이션의 특정 영역에만 영향을 주므로 전체 스파크 애플리케이션이나 스파크 잡에는 영향을 미치지 않습니다.
동적 할당
스파크 워크로드에 따라 애플리케이션이 차지할 자원을 동적으로 조절하는 메커니즘을 제공합니다.
사용자 애플리케이션은 더 이상 사용하지 않는 자원을 클러스터에 반환하고 필요할 때 다시 요청할 수 있습니다.
spark.dynamicAllocation.enabled 속성값을 true로 설정
데이터 지역성(data locality)

http://www.datascienceassn.org/content/data-locality-hpc-vs-hadoop-vs-spark
기본적으로 네트워크를 통해 데이터 블록을 교환하지 않고 특정 데이터를 가진 노드에서 동작할 수 있도록 지정하는 것을 의미합니다.
직접적인 성능 향상 기법
병렬화
spark.defaul.parallelism과 spark.sql.shuffle.partitions의 값을 클러스터 코어 수에 따라 설정합니다.
스테이지에서 처리해야할 데이터양이 매우 많다면 클러스터의 CPU 코어당 최소 2~3개의 태스크를 할당합니다.
파티션 재분배와 병합
파티션 재분배 과정은 셔플을 수반함, 클러스터 전체에 걸쳐 데이터가 균등하게 분배되므로 잡의 전체 실행 단계를 최적화합니다.
일반적으로 가능한 한 적은 양의 데이터를 셔플하는 것이 좋습니다.
셔플 대신 동일 노드의 파티션을 하나로 합치는 coalesce 메서드를 실행해 DataFrame이나 RDD의 전체 파티션 수를 먼저 줄옇야 함, 이보다 느린 repartition 메서드는 부하를 분산하기 위해 네트워크로 데이터를 셔플링합니다.
파티션 재분배는 조인이나 cache 메서드를 호출 시 매우 유용합니다.
파티션 재분배 과정은 부하를 유발하지만 애플리케이션의 전체적인 성능과 스파크 잡의 병렬성을 높일 수 있음을 기억해야합니다.
향상된 필터링
사용자 정의 파티셔닝
잡이 여전히 느리게 동작하거나 불안정하다면 RDD를 이용한 사용자 정의 파티셔닝 기법을 적용합니다.
사용자 정의 함수(UDF)
임시 데이터 저장소(캐싱)
https://livebook.manning.com/book/spark-in-action-with-examples-in-java/16-cache-and-checkpoint-enhancing-spark-s-performances/v-14/185
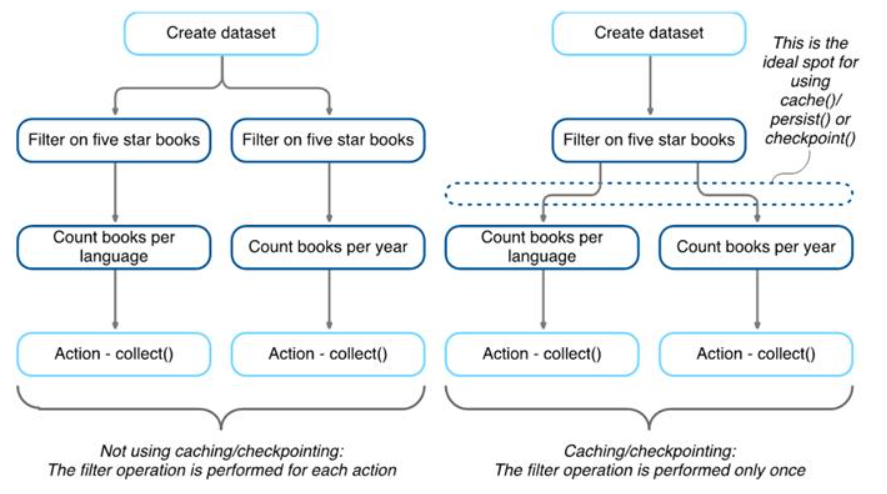
애플리케이션에서 같은 데이터셋을 계속해서 재사용한다면 캐싱을 사용해 최적화할 수 있습니다.
캐싱은 클러스터의 익스큐터 전반에 걸쳐 만들어진 임시 저장소(메모리나 디스크)에 DataFrame, 테이블 또는 RDD를 보관해 빠르게 접근할 수 있도록 합니다
캐싱이 필요한 상황 : 스파크의 대화형 세션이나 스탠드얼론 애플리케이션에서 특정 데이터셋(DataFrame 또는 RDD)을 다시 사용하려 할 경우
캐싱은 지연 연산, 데이터에 접근해야 캐싱이 일어납니다.
DataFrame의 cache 메서드를 호출하면 스파크는 최초 연산 시 데이터를 메모리나 디스크에 저장함, 다음 캐싱된 DataFrame을 사용하는 쿼리를 수행하면 원본 파일을 읽는 대신 메모리에 저장된 데이터를 참조합니다.
캐싱은 지연 처리, 스파크는 DataFrame에 액션을 실행하는 시점에 데이터를 캐싱합니다.
캐싱은 동일한 데이터를 여러 번 접근하는 반복적인 머신러닝 워크로드에도 매우 적합합니다.
스파크의 cache 명령은 기본적으로 데이터를 메모리에 저장합니다.
클러스터 전체 메모리가 가득 찼다면 데이터셋의 일부 데이터만 캐싱합니다.
정교한 제어를 위해 persist 메서드를 사용함, persist 메서드는 데이터 캐시 영역(메모리, 디스크 또는 둘 다)을 지정하는 StorageLevel 객체를 파라미터로 사용합니다.
조인
동등 조인은 최적화하기 가장 쉬우므로 우선적으로 사용하는 것이 좋습니다.
조인 순서 변경은 내부 조인을 사용해 필터링하는 것과 동일한 효과를 누림, 안정성과 최적화를 위해 카테시안 조인이나 전체 외부 조인의 사용을 최대한 피해야 합니다.
데이터를 적절하게 버켓팅하면 조인 수행 시 거대한 양의 셔플이 발생하지 않도록 미리 방지할 수 있습니다.
집계
집계 전에 충분히 많은 수의 파티션을 가질 수 있도록 데이터를 필터링하는 것이 최선의 방법입니다.
Reference
https://www.amazon.com/Spark-Definitive-Guide-Processing-Simple/dp/1491912219
https://sparkbyexamples.com/spark/spark-performance-tuning/?amp=1#udf
https://mageswaran1989.medium.com/spark-optimizations-for-advanced-users-spark-cheat-sheet-d74464618c20
Last updated