presto_base
Presto Base

https://www.starburst.io/learn/open-source-presto/presto-connectors/
Presto는 기가바이트에서 페타바이트에 이르는 다양한 데이터 소스에 대해 빠른 분석 쿼리를 실행하기 위한 오픈 소스 분산 SQL 엔진입니다.
Presto는 대화형 데이터 분석을 위한 널리 사용되는 분산 SQL 쿼리 엔진입니다.
대화형 분석 : 사용자가 입력한 쿼리에 바로 반응하여 결과를 반환하는 분석 방법입니다.
Presto는 낮은 대기 시간을 위해 설계되었으며 클래식 MPP 아키텍처를 따릅니다. 메모리 내 스트리밍 셔플을 사용하여 낮은 대기 시간을 달성합니다.
Presto에는 연결된 작업자 풀이 있는 클러스터당 단일 공유 코디네이터가 있습니다. Presto는 다중 테넌시를 지원하기 위해 동일한 Presto 작업자(공유 실행기)에서 가능한 한 많은 쿼리를 예약하려고 합니다.
MPP(Massively Parallel Processing) 아키텍처를 통해 시간과 비용이 많이 드는 ETL 프로세스 없이 대규모 데이터 세트를 직접 쿼리할 수 있습니다.
Presto의 아키텍처는 연결할 수 있는 데이터 소스를 완전히 추상화하여 컴퓨팅과 스토리지의 분리를 용이하게 합니다. 커넥터 SPI를 사용하면 파일 시스템 및 개체 저장소, NoSQL 저장소, 관계형 데이터베이스 시스템 및 사용자 지정 서비스용 플러그인을 구축할 수 있습니다
Presto는 단순히 데이터가 있는 곳에서 데이터를 쿼리할 수 있기 때문에 긴 ETL 프로세스를 수행할 필요가 없습니다.
Presto의 원래 사용 사례는 대화형 분석, 소규모 Batch ETL 작업 및 A/B 테스트에 속합니다.
온라인 분석 처리 워크로드를 처리하며 최근에는 Presto가 삽입을 보다 효율적으로 처리하는 기능을 추가했지만 Presto는 데이터 웨어하우스 또는 데이터 레이크에서 데이터를 읽고 연합하는 경우 빛을 발합니다.
Presto는 데이터 소비자의 데이터 액세스에 대해 보다 민첩한 접근 방식을 제공할 수 있습니다.
Architecture
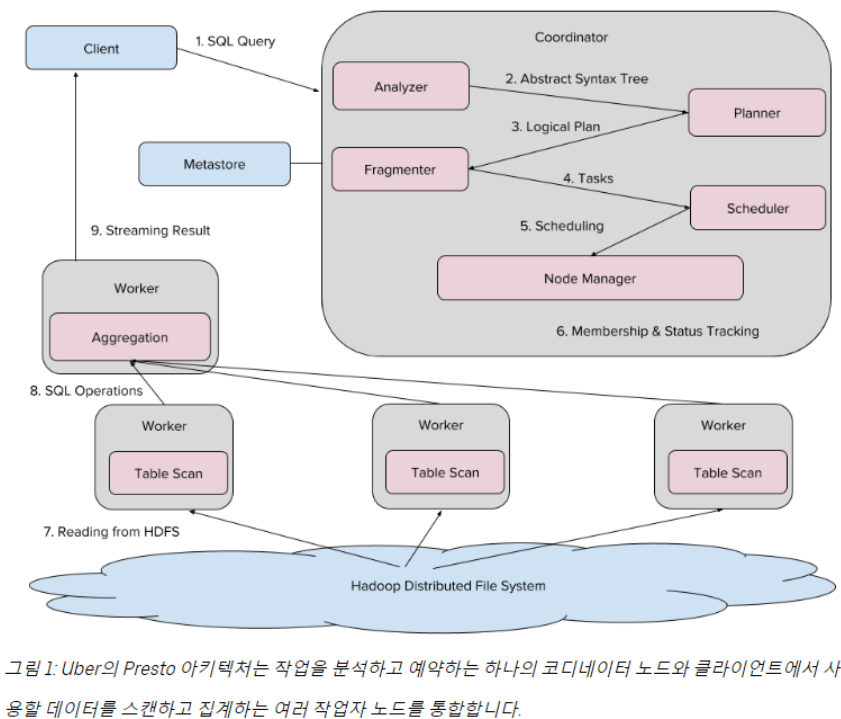
https://www.uber.com/blog/presto/
Uber의 Presto 생태계는 Hadoop에 저장된 데이터를 처리하는 다양한 노드로 구성됩니다. 각 Presto 클러스터에는 SQL을 컴파일하고 작업을 예약하는 하나의 "코디네이터" 노드와 공동으로 작업을 실행하는 여러 "작업자" 노드가 있습니다. 클라이언트는 SQL 쿼리를 Presto 코디네이터에게 보냅니다. Presto 코디네이터의 분석기는 SQL을 AST (추상 구문 트리 )로 컴파일합니다.
여기에서 플래너는 AST를 쿼리 계획 으로 컴파일하여 계획을 작업으로 분할하는 프래그먼트에 맞게 최적화합니다. 다음으로 스케줄러는 HDFS(Hadoop 분산 파일 시스템)에서 파일을 읽거나 집계를 수행하는 각 작업을 특정 작업자에게 할당하고 노드 관리자는 진행 상황을 추적합니다. 마지막으로 이러한 작업의 결과는 클라이언트로 스트리밍됩니다.
Presto는 쿼리 전용 엔진이기 때문에 컴퓨팅과 스토리지를 분리하고 다양한 커넥터를 사용하여 다양한 데이터 소스에 연결합니다.
Presto는 쿼리 중인 데이터에 대한 메타데이터(테이블, 열, 데이터 유형)에 Apache Hive 메타데이터 카탈로그를 사용합니다.
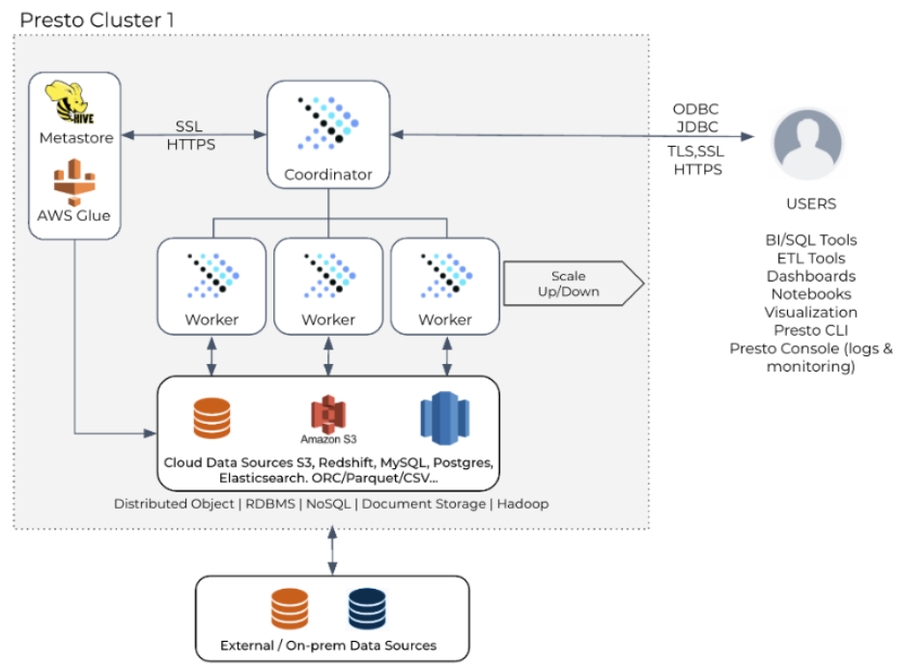
Presto 클러스터는 코디네이터와 작업자라는 두 가지 유형의 노드로 구성됩니다.
코디네이터 노드는 EMR 리더 노드에서 실행되고 작업자 노드는 EMR 코어 노드 및 선택적으로 EMR 작업 노드(EMR 클러스터의 나머지 노드)에서 실행합니다.
리더 노드 : Presto 클러스터에는 하나의 리더 노드가 필요합니다. 이 노드는 쿼리 예약 및 실행을 관리합니다. Amazon EMR 5.23.0 이상에서는 3개의 리더 노드가 있는 클러스터를 시작하여 고가용성을 지원할 수 있습니다.
코어 노드 : 코어 노드는 HDFS를 실행합니다. 즉, 확장 속도가 느리고 적극적으로 확장하면 안 됩니다. 대규모 중간 데이터 세트에 HDFS 스토리지가 필요하지 않은 경우 작업 노드를 사용하는 것이 더 나은 옵션입니다. 데이터가 Amazon S3에 있는 경우 HDFS가 제한되거나 필요하지 않으므로 최소한의 코어 노드만 필요합니다. 하나의 코어 노드는 EMR 클러스터의 최소 요구 사항입니다. HA 및 장애 조치 목적으로 두 개 이상의 코어 노드를 실행하는 것이 좋습니다.
작업 노드 : 작업 노드는 컴퓨팅 작업자 역할을 하며 HDFS를 실행하지 않으므로 동적 로드 요구 사항이 있는 적극적인 자동 확장에 적합합니다. 작업 노드는 HDFS 스토리지를 제공하지 않기 때문에 크기를 조정하는 동안 클러스터에서 빠르게 추가하고 제거할 수 있습니다. Presto는 HDFS를 활용하지 않지만 코어 노드를 클러스터에 추가하고 등록하는 것은 여전히 작업 노드를 추가하는 것보다 더 큰 오버헤드가 있습니다.
Ganglia 와 같은 시스템 모니터링 도구를 사용하여 클러스터의 로드, 메모리 사용량, CPU 사용률 및 네트워크 트래픽을 모니터링합니다.
실행 계획

https://trino.io/blog/2019/05/30/semijoin-precomputed-hasd.html
Presto는 쿼리 계획을 여러 노드에서 병렬로 실행할 수 있는 단계라는 부분으로 나누고 각 노드는 서로 다른 데이터 세트에서 작동합니다. 단계에는 두 가지 유형이 있습니다
리프 단계: 쿼리 계획의 리프에 있고 Hive 테이블과 같은 데이터 소스에서 데이터를 읽는 단계입니다.
중간 단계: 리프 단계 이외의 단계로 다른 업스트림 단계의 데이터를 처리합니다.
작업자 는 Exchange출력을 섞고 업스트림 단계에서 중간 단계로 전송합니다. GROUP BY및 와 같은 특정 연산자 JOIN의 경우 리프 단계의 출력 데이터는 열 값으로 분할되며 셔플 작업은 특정 파티션이 항상 중간 단계의 동일한 작업에 의해 처리되도록 합니다
GROUP BY 이 분할은 교환 중에 해당 열의 값에 대한 해시를 계산해야 하며 나중에 중간 단계에서 또는 JOIN작업 을 실행하는 동안 동일한 해시가 필요 합니다. 중복 계산을 방지하기 위해 Presto는 리프 단계에서 이 해시 값을 계산하고 연산자에서 사용 Exchange하며 중간 단계에서 사용하도록 출력에서 사용할 수 있도록 합니다.
리프 단계( Stage2)는 데이터 소스에서 테이블을 읽고 부분적으로 집계된 데이터를 Stage1최종 집계가 발생하는 위치로 공급하며 마지막으로 를 통해 결과를 사용할 수 있습니다 Stage0에 의해 생성된 각 행 은 동일한 도시에 대한 데이터가 의 동일한 작업에 의해 처리되도록 하기 위해 그 안에 있는 열의 Stage2값으로 분할되어야 합니다.
Unnest
Unnest는 Facebook의 일일 Presto 워크로드에서 일반적인 작업입니다. ARRAY, MAP, 또는 ROW를 평면 관계로 변환합니다
Reference
https://www.starburst.io/learn/open-source-presto/
https://prestodb.io/blog/2020/08/20/unnest
https://aws.amazon.com/ko/blogs/big-data/top-9-performance-tuning-tips-for-prestodb-on-amazon-emr/
Last updated