조인과 셔플
스파크의 조인 수행 방식
노드간 네트워크 통신 전략
스파크는 조인 시 두가지 클러스터 통신 방식을 활용합니다.
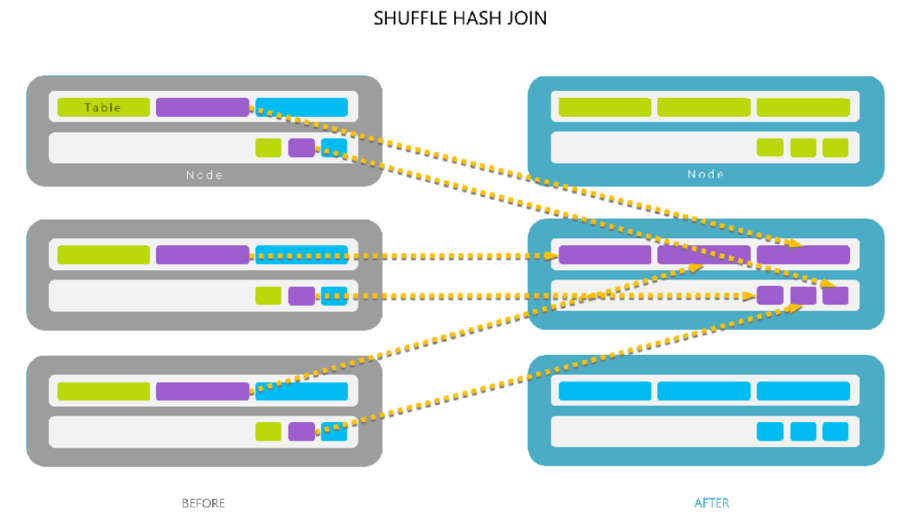
전체 노드간 통신을 유발 셔플 조인(shuffle join)
https://jixjia.com/shuffle-vs-broadcast/
각 테이블에 대한 클러스터의 모든 데이터를 클러스터의 지정된 노드로 이동
조인 키로 두 데이터 세트를 섞고 동일한 키를 가진 데이터를 동일한 노드로 이동합니다.
때때로 셔플 조인은 고르지 않은 샤딩 (즉, 하나의 데이터 세트가 조인 중인 다른 데이터 세트보다 상당히 큼)이 있거나 병렬 처리가 제한되어 있을 때 (예: 요일 필드에 조인하면 최대 7개의 출력 파티션이 제공될 때 ) 문제가 될 수 있습니다
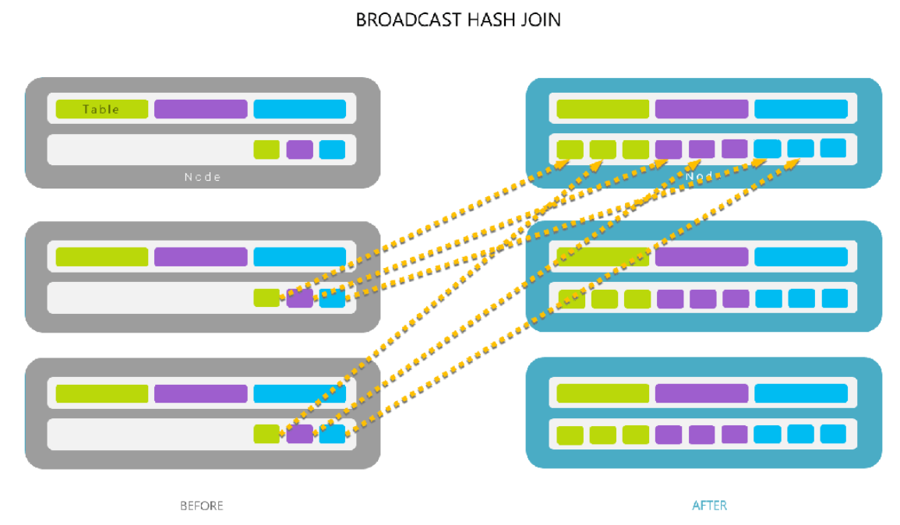
그렇지 않은 브로드캐스트 조인(broadcast join)
https://jixjia.com/shuffle-vs-broadcast/
작은 DataFrame을 클러스터의 전체 워커 노드에 복제하는 것으로 대규모 노드 간 통신이 발생하지만 그 이후로는 노드 사이에 추가적인 통신이 발생하지 않습니다.
모든 단일 노드에서 개별적으로 조인이 수행되므로 CPU가 가장 큰 병목 구간, 너무 큰 데이터를 브로드캐스트하면 고비용의 수집 연산이 발생하므로 드라이버 노드가 비정상적으로 종료됩니다.
Broadcast 방식은 작은 사이즈의 테이블 (DataFrame) 을 Driver를 거쳐 각 Worker 노드에 전부 뿌린 뒤 Shuffle 없이 Join을 진행합니다.따라서 Broadcast 되는 대상 테이블이 크다면 Driver 의 메모리가 터질 수 있습니다
전체 데이터 Shuffle 이 없이 작은 테이블만 전송하므로, 전체 네트워크를 통한 데이터 이동이 없어 Join 속도가 매우 빠릅니다.
내부 최적화 기술은 시간이 흘러 비용 기반 옵티마이저(cost-based optimizer, CBO)가 개선되고 더 나은 통신 전략이 도입되는 경우 바뀔 수 있습니다.
노드별 연산 전략
조인 전략

https://blog.clairvoyantsoft.com/apache-spark-join-strategies-e4ebc7624b06
Equi Join 의 경우 Broadcast, Shuffle Hash, Sort Merge, Shuffle Replicate NL 전략이 사용 가능합니다
Non Equi Join 의 경우 Broadcast, Shuffle Replicate NL 전략만 사용이 가능합니다.

https://dataninjago.com/2022/01/11/spark-sql-query-engine-deep-dive-11-join-strategies/
Shuffle

https://0x0fff.com/spark-architecture-shuffle/
각 테이블에 대한 클러스터의 모든 데이터를 클러스터의 지정된 노드로 이동합니다.
조인 키로 두 데이터 세트를 섞고 동일한 키를 가진 데이터를 동일한 노드로 이동합니다.
때때로 셔플 조인은 고르지 않은 샤딩 (즉, 하나의 데이터 세트가 조인 중인 다른 데이터 세트보다 상당히 큼)이 있거나 병렬 처리가 제한되어 있을 때 (예: 요일 필드에 조인하면 최대 7개의 출력 파티션이 제공될 때 ) 문제가 될 수 있습니다
Sort Merge Join

https://towardsdatascience.com/the-art-of-joining-in-spark-dcbd33d693c

https://towardsdatascience.com/strategies-of-spark-join-c0e7b4572bcf
Sort Merge Join 파티션은 조인 작업 전에 조인 키를 기준으로 정렬됩니다.
실제 작업을 실행하기 전에 먼저 파티션을 정렬합니다.
Sort Merge Joins는 특히 Shuffle Hash Joins와 비교할 때 클러스터에서 데이터 이동을 최소화하는 경향이 있습니다.
정렬 조인은 먼저 조인 키를 기반으로 관계를 정렬한 다음 두 데이터 세트를 병합합니다
Hash Join

https://towardsdatascience.com/strategies-of-spark-join-c0e7b4572bcf
해시 조인은 먼저 더 작은 릴레이션의 join_key를 기반으로 해시 테이블을 생성한 다음 해시된 join_key 값과 일치하도록 더 큰 릴레이션을 반복하면서 수행됩니다.
스파크에서 Hash Join은 노드 수준별로 역할을 수행하며 전략은 노드에서 사용 가능한 파티션을 조인하는 데 사용됩니다.
Broadcast Join

https://towardsdatascience.com/the-art-of-joining-in-spark-dcbd33d693c
브로드캐스트 조인에서는 작은 테이블의 복사본이 모든 실행자에게 전송됩니다. 그런 다음 각 실행자는 네트워크 통신 없이 조인을 수행합니다.
브로드캐스트 조인은 Spark가 모든 실행자 노드에 테이블 사본 을 보내기로 결정할 때 발생합니다.
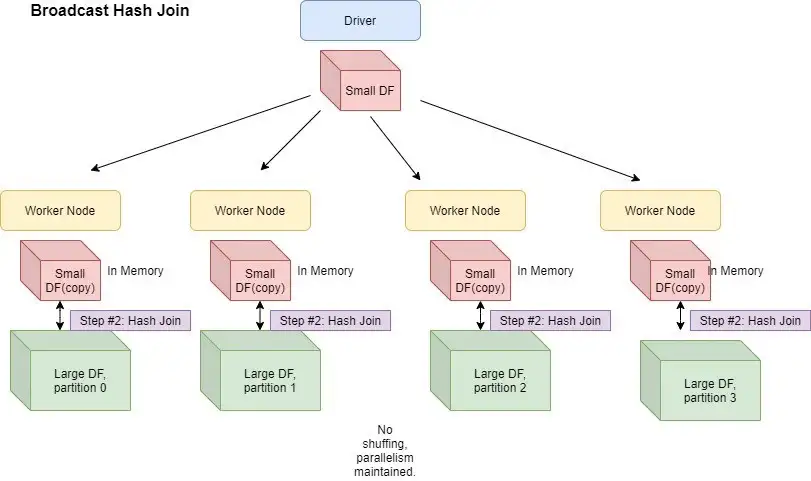
Broadcast Hash Join
https://towardsdatascience.com/strategies-of-spark-join-c0e7b4572bcf
브로드캐스트 해시 조인에서 관계 중 하나의 복사본이 join 모든 작업자 노드로 전송되고 셔플링 비용이 절약 됩니다. 이는 큰 관계를 작은 관계와 조인할 때 유용합니다. map-side 조인(작업자 노드를 매퍼와 연결)이라고도 합니다.
데이터 프레임 중 하나가 작고 메모리에 맞으면 모든 실행기에 브로드캐스팅되고 해시 조인이 수행됩니다.
Shuffle Hash Join

https://towardsdatascience.com/strategies-of-spark-join-c0e7b4572bcf
동일한 Executor 노드에서 동일한 Join Key 값으로 데이터를 이동한 후 Hash Join(위에서 설명)을 수반합니다. 조인 조건을 출력 키로 사용하면 실행기 노드 간에 데이터가 섞이고 마지막 단계에서 동일한 키의 데이터가 동일한 실행기에 존재할 것임을 알기 때문에 데이터가 해시 조인을 사용하여 결합됩니다.
테이블이 상대적으로 큰 경우 브로드캐스트를 사용하면 드라이버 및 실행기 측 메모리 문제가 발생할 수 있습니다. 이 경우 Shuffle Hash Join이 사용됩니다. 셔플링과 해싱이 모두 포함되므로 비용이 많이 드는 조인입니다. 또한 해시 테이블을 유지하기 위한 메모리와 계산이 필요합니다.
1단계 : 셔플링: 조인 테이블의 데이터는 조인 키를 기준으로 분할됩니다. 해당 파티션에 할당된 레코드의 동일한 조인 키를 갖도록 파티션 간에 데이터를 섞습니다.
2단계 : 해시 조인: 각 파티션의 데이터에 대해 고전적인 단일 노드 해시 조인 알고리즘이 수행됩니다.
Sort Merge 조인은 기본 조인이며 셔플 해시 조인보다 선호됩니다.
Shuffle Hash Join의 성능은 조인하려는 키와 데이터가 고르게 분포되어 있고 병렬화를 위한 키 수가 적절할 때 가장 좋습니다.
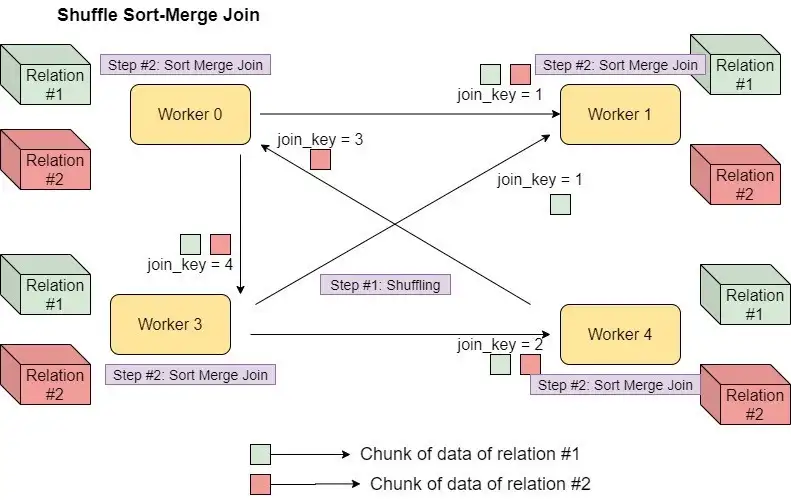
Shuffle Sort Merge Join
https://towardsdatascience.com/strategies-of-spark-join-c0e7b4572bcf
셔플 정렬-병합 조인에는 데이터를 셔플하여 동일한 작업자와 동일한 join_key를 얻은 다음 작업자 노드의 파티션 수준에서 정렬-병합 조인 작업을 수행하는 작업이 포함됩니다.
SMJ(Shuffle Sort-merge Join)는 데이터를 셔플하여 동일한 작업자와 동일한 조인 키를 얻은 다음 작업자 노드의 파티션 수준에서 정렬-병합 조인 작업을 수행하는 작업을 포함합니다. 조인 작업 전에 파티션이 조인 키에 따라 정렬됩니다.
셔플 단계
두 데이터 세트의 데이터를 읽고 섞습니다. 셔플 작업 후 두 데이터 세트의 동일한 키를 가진 레코드는 셔플 후 동일한 파티션에 있게 됩니다. 전체 데이터 세트는 이 조인으로 브로드캐스트되지 않습니다. 즉, 각 파티션의 데이터 세트는 셔플 후 관리 가능한 크기가 됩니다.
정렬 단계
양쪽의 레코드는 키별로 정렬됩니다. 해싱 및 버킷팅은 이 조인과 관련이 없습니다.
병합 단계
조인은 정렬된 데이터 세트의 레코드를 반복하여 수행됩니다. 데이터 세트가 정렬되었으므로 키 불일치가 발생하는 즉시 요소에 대한 병합 또는 조인 작업이 중지됩니다. 따라서 모든 키에 대해 조인 시도가 수행되지는 않습니다.
Cartesian Product Join
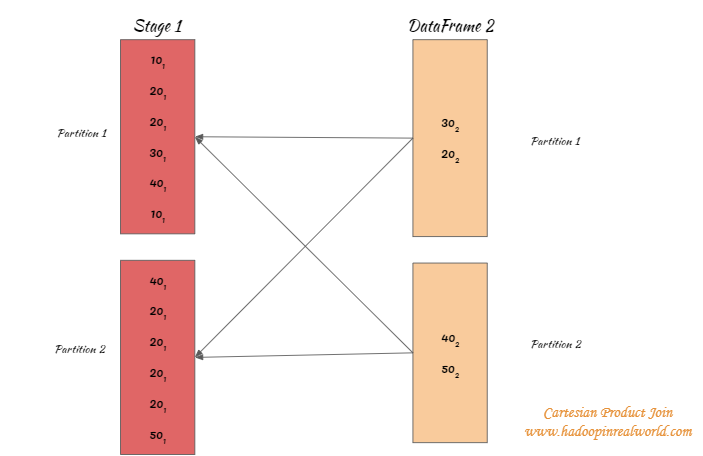
https://www.hadoopinrealworld.com/how-does-cartesian-product-join-work-in-spark/
Shuffle-and-Replication Nested Loop Join이기도 하며 데이터 세트가 브로드캐스트되지 않는다는 점을 제외하면 브로드캐스트 중첩 루프 조인과 매우 유사하게 작동합니다.
조인을 평가하기 위해 두 관계의 데카르트 곱(SQL과 유사)을 계산합니다.
데카르트 곱 조인은 두 조인 관계의 곱을 계산하는 것입니다. 상상할 수 있듯이 데카르트 제품 조인의 성능은 대규모 관계에서 매우 나빠질 수 있으므로 이러한 유형의 조인은 피해야 합니다.
Broadcast Nested Loop Join

https://www.hadoopinrealworld.com/how-does-broadcast-nested-loop-join-work-in-spark/
브로드캐스트 중첩 루프 조인에는 셔플 또는 정렬이 포함되지 않습니다. 두 데이터셋 중 가장 작은 데이터셋은 모든 파티션에 브로드캐스팅되고 두 데이터셋 사이에 중첩된 루프가 수행되어 조인을 수행합니다. 데이터세트 1의 모든 레코드는 데이터세트 2의 모든 레코드와 조인하려고 시도합니다.
Reference
https://www.amazon.com/Spark-Definitive-Guide-Processing-Simple/dp/1491912219
https://1ambda.blog/2021/12/27/practical-spark-9/
https://eyeballs.tistory.com/248
https://blog.clairvoyantsoft.com/apache-spark-join-strategies-e4ebc7624b06
https://dataninjago.com/2022/01/11/spark-sql-query-engine-deep-dive-11-join-strategies/
Last updated